
챗GPT를 필두로 대규모언어모델(LLM) 및 생성 인공지능 (Generative AI)을 위한 시스템 개발에 글로벌 기업들이 총력전을 펼치는 가운데, 국내 시스템 반도체 스타트업이 차세대 연결 기술 컴퓨트 익스프레스 링크(Compute eXpress Link, CXL)을 기반으로 확장가능한 메모리와 높은 성능을 제공하는 AI 가속 시스템을 개발해 국내외 큰 주목을 받고 있다.
이는 지난해, 대용량 메모리 장치부터 프로세스를 포함한 컴퓨트 익스프레스 링크(CXL) 2.0 기반의 차세대 메모리 확장 플랫폼 ‘다이렉트CXL(DirectCXL)’개발을 이끌고 세계 최초로 프로토타입 제작, 운영체제가 실장된 단대단(End-to-End) 시연까지 성공시킨 KAIST 전기및전자공학부 정명수 교수의 교수창업기업 '파네시아(Panmesia. 대표 정명수 교수)'의 이야기로 지난해 8월 설립된 파네시아는 먼저, 해외에서 그 기술력과 시장성에 큰 주목을 이끌고 국내로 이어지고 있다.
이 기술은 한마디로 "GPU가 초대용량(최대 4페타바이트)의 메모리를 활용할 수 있도록 해주는 기술"로 요약할 수 있다. 즉, 단 몇 대의 GPU만으로도 챗GPT, 추천시스템과 같은 대규모 머신러닝 모델을 구동할 수 있게 되기 때문에, 데이터센터 구축·운영 비용을 크게 절감할 수 있는 것이다.

시스템은 CXL 메모리 인터페이스를 기반으로 GPU와 대용량 뉴메모리 기반의 메모리확장장치(Memory expander)를 연결하여 구성한 AI 가속 시스템으로 GPU에 최대 4PB(10^15 byte)의 확장가능한 메모리를 제공함과 동시에, 기존 PCIe 기술을 기반으로 대용량 메모리를 연결한 시스템 대비 AI 모델의 학습시간을 5.3배 단축할 수 있다.
특히, 보유한 AI의 품질과 성능이 곧 기업의 경쟁력을 좌우하는 요소로 떠오르며, 글로벌 기업들은 앞다투어 자사 AI의 정확도를 높이기 위해 모델의 크기를 키우고 있다. 이에 따라, 테라바이트(10^12 byte) 수준 이상의 대규모 AI를 처리할 수 있는 컴퓨팅 시스템에 대한 업계의 관심이 높아지고있다.
한편, 대표적인 AI 가속장치인 GPU는 DRAM 기술의 한계로 인해 내부 메모리 용량이 수십 기가바이트(10^9 byte)에 머물러 있어 대규모 모델을 지원하기에는 그 용량이 턱없이 부족한 실정이다. 이를 위해 기존 시스템은 GPU의 메모리를 저장장치인 솔리드 스테이트 드라이브(SSD)를 이용하여 확장하는 방법을 시도했으나, SSD의 느린 임의읽기 성능과 SSD-GPU간 데이터 이동으로 인해 그 성능이 매우 제한적이었다.
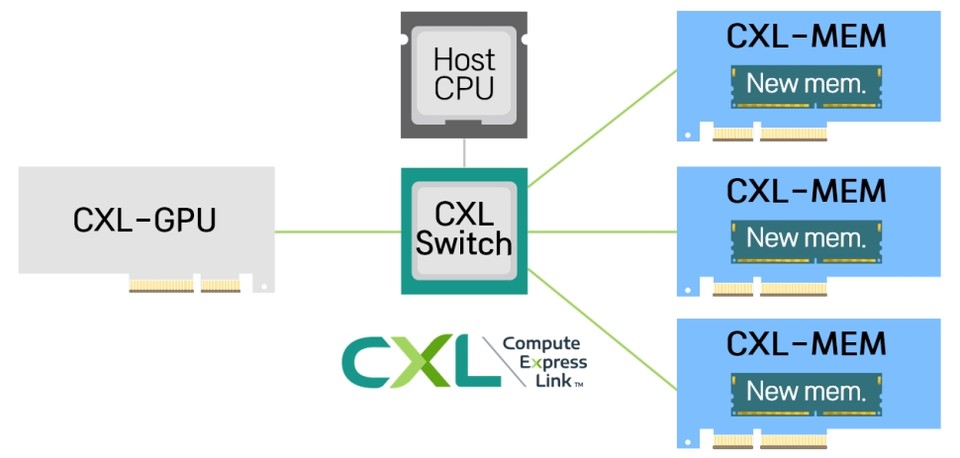
이를 위해 정 교수는 차세대 메모리 인터페이스에 출사표를 던진 것이다. 파네시아는 학술공동연구를 통해 CXL 인터페이스를 통해 대용량의 메모리 공간을 제공하는 메모리확장장치를 GPU와 연결한 AI 가속시스템을 개발한 것이다. 개발한 이 시스템 '트레이닝CXL(TrainingCXL)'은 대용량 뉴메모리(New memory)를 탑재한 메모리확장장치와 GPU를 레고블럭 조립하듯 자유롭게 연결하여 GPU에 대용량의 메모리 공간을 제공한다.
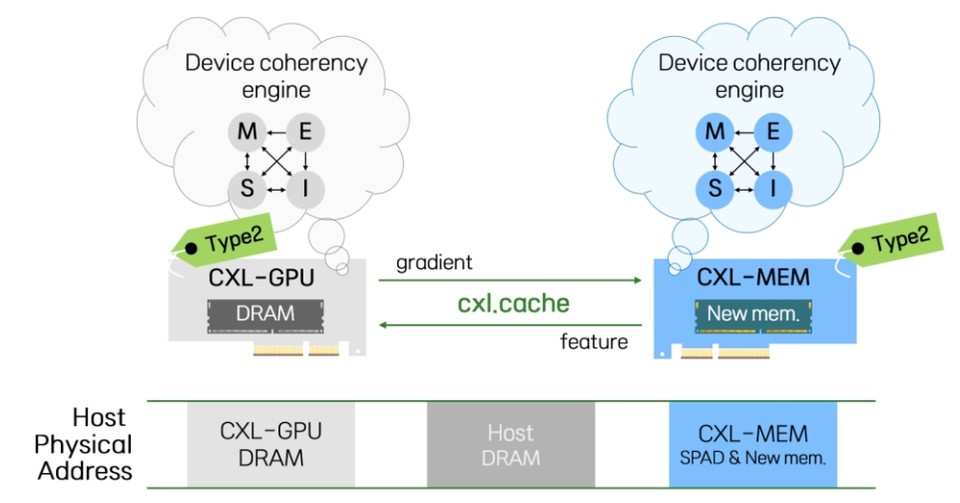
특히, 이 시스템의 핵심은 차세대 메모리 인터페이스인 CXL이다. CXL은 시스템의 장치 간 연결을 위한 프로토콜로, 이 프로토콜을 지원하는 시스템은 CPU, GPU, 메모리확장장치와 같은 다수의 장치를 자유롭게 연결하면서도 장치 간에 고속으로 데이터를 주고받을 수 있는 것을 특징으로 한다.
이러한 특징 덕분에, CXL은 글로벌 빅테크 기업의 데이터센터나 고성능컴퓨터에서 사용자 응용에 대용량 메모리를 제공할 방법으로 부상하고 있다. 공동연구진은 CXL을 통해 메모리확장장치를 GPU와 연결하여 GPU에 대용량 메모리를 제공하면서, 장치 간 데이터 이동으로 인한 실행시간 지연을 최소화했다.
아울러, 이번 연구는 CXL 프로토콜이 정의하는 여러가지 서브프로토콜 중 cxl.cache를 사용하여 GPU 및 메모리확장장치가 능동적으로 데이터를 주고받을 수 있도록 설계했다. cxl.cache를 통한 능동적인 고속 데이터 이동은 데이터 이동시간이 장치의 계산시간에 가려져 사용자에게 드러나지 않도록 하고, 추가적인 소프트웨어의 개입을 제거하여 높은 성능을 이끌어낸 것이다.
또한, 대용량의 메모리를 제공할 뿐 아니라, 메모리확장장치에 목표 응용을 위한 처리 능력을 부여하여 실행시간을 단축했으며, 목표 응용은 유튜브, 인스타그램과 같은 서비스에서 사용자에게 알맞은 콘텐츠를 추천해주는 역할을 해주는 추천시스템(Recommendation Systems)이다.
추천시스템은 각 사용자에게 맞는 추천을 위해 수억명의 사용자 및 콘텐츠 각각에 대한 정보(임베딩 벡터, embedding vector)를 AI 모델에 포함하여 모델의 크기가 수십 테라바이트에 이른다.
이는 최근 주목받고 있는 생성형 AI 모델 챗GPT의 수 배에 달하는 크기로, 실행을 위해 대용량의 메모리가 꼭 필요하다. 연구진은 추천시스템 모델의 임베딩 벡터를 메모리확장장치에 저장하고, 메모리확장장치 내부에 임베딩 벡터를 처리할 수 있는 가속모듈을 탑재했다.
가속모듈은 모델 학습 시 임베딩 벡터를 빠르게 처리할 뿐 아니라, 시스템이 원본 임베딩 벡터 대신 처리를 통해 크기가 작아진 벡터를 GPU에 전송하도록하여 데이터 이동량과 시간을 줄여준다. 원본 임베딩 벡터가 거대한 원석이라면, 처리한 벡터는 가공된 반지라고 비유할 수 있다.
예를 들어, 고객에게 반지를 전달하고자할 때, 고객 근처까지 거대한 원석을 모두 운송한 다음 가공하는 대신 원석의 산지 근처에서 원석을 반지로 가공한다음 반지만을 전달하는 것이 운송에 필요한 노력과 운송량을 줄일 수 있는 것과 같다.
개발된 시스템은 기존 PCIe 기술을 기반으로 대용량 뉴메모리를 연결한 최신 시스템 대비 다양한 종류의 추천시스템 모델을 이용한 평가에서 학습시간을 5.3배 단축하여 그 효과를 보였다. 트레이닝CXL은 대규모 AI를 위한 차세대 시스템 설계에 CXL을 활용할 방향을 제시할 수 있을 것으로 기대된다.
정명수 파네시아 대표는 “메모리 반도체의 미래 먹거리인 CXL 기술을 선도하여 관련 시장과 환경을 활성화하기 위해 앞으로도 꾸준히 높은 수준의 연구성과를 공개하고 많은 반도체 및 시스템 회사들이 CXL을 사용할 수 있도록 관련 인프라를 제공할 것”이라며 포부를 밝혔다.
이번 연구성과는 국제 학술지인 IEEE Micro 3-4월호에 “Failure Tolerant Training with Persistent Memory Disaggregation over CXL(아카이브 다운)” 라는 제목의 논문으로 게재됐다.
또한, 최근 캐나다 몬트리올 국제 최우수 학술대회인 국제 고성능 컴퓨터 구조, IEEE International Symposium on High-Performance Computer Architecture (HPCA)의 워크샵에서 초청강연을 통해 발표된 바 있으며 오는 5월에는 미국 플로리다에서 열리는 국제 병렬 빛 분산 처리 심포지움, International Parallel and Distributed Processing Symposium (IPDPS)의 워크샵에서도 초청강연을 통해 소개될 예정이다.
한편, CXL은 데이터센터와 고성능 컴퓨터의 메모리 요구를 충족시켜줄 차세대 표준으로 각광받고 있지만, 아직은 개발의 초기 단계에 머물러 그의 효율적인 활용방법을 여러 글로벌 기업들이 고심하고 있는 상황이다.
트레이닝 CXL은 대규모 AI를 위한 차세대 시스템 설계에 CXL을 활용할 방향을 제시하여 이러한 기술의 발전을 선도할 수 있다. 경제적으로, 트레이닝 CXL은 값비싼 GPU를 수 백 대씩 구매하지 않고도 추천시스템, 챗 GPT와 같은 대규모 AI 모델을 효율적으로 실행할 수 있도록 하여 시스템의 구성 비용을 크게 낮추고, 데이터 근처 처리를 통해 데이터 이동을 줄이고, 저전력의 뉴메모리를 사용하여 시스템의 소비전력 및 탄소배출량을 낮추어 탄소중립에 기여할 수 있을 것으로 전망된다.